22 April 2023
Squeeze more out of your GPU for LLM inference—a tutorial on Accelerate & DeepSpeed
What: Eng blog post
Written for: Gradient AI (formerly known as Preemo), freelance
Links: Original Preemo Medium post, current Gradient AI blog post
My role: Technical editor. Worked efficiently with the engineer and author, for whom English is a second language. Suggested creating the first two diagrams. We met twice, first at the start to understand the content, and again after a few rounds of async edits, to do a final review and to workshop the title.
A driving question
“How do ML practitioners handle LLM inference without sacrificing latency or throughput?”
During my most recent project, I wanted to test how current large language models (LLMs) from Hugging Face perform on code generation tasks against the HumanEval dataset. I spun up a P3 instance from AWS with a V100 GPU and wrote a test framework using Hugging Face and PyTorch. The framework loaded each model checkpoint into the GPU, ran batch inference, then scored the model based on pass@K¹. It was smooth sailing until I hit the model EleutherAI/gpt-j-6b. Its checkpoint is 24.2GB — bigger than V100’s 16 GB memory — so of course it threw a CUDA Out Of Memory error right at my face.
I knew I could modify my code to run on the CPU, or give AWS and Nvidia more money to get a bigger GPU. But even the best GPU in the universe today (A100) has only 80GB memory, and LLM sizes today can easily exceed this number. I thought there must be a better way.
¹ pass@K is a metric measuring the code generation accuracy defined in this paper.
Enter: Accelerate and DeepSpeed
That’s how I fell into the rabbit hole of researching the latest inference technologies for large Hugging Face models. In this post, I share how and when to use two libraries — Accelerate and DeepSpeed — including workarounds for errors you might run into during setup.
Here are the two major questions I resolved:
If a model can’t fit on a GPU, how do I offload part of the model onto the CPU? (And, does offloading part of the model have advantages over just using the CPU?)
If a model does fit on a GPU, how can we further accelerate inference?
To answer these two questions, I experimented with two libraries: Accelerate (Hugging Face) and DeepSpeed (Microsoft).
Within DeepSpeed, there are two different technologies, ZeRO-Inference and DeepSpeed Inference. These two technologies are combined into a framework called DeepSpeed Model Implementation for Inference (MII).
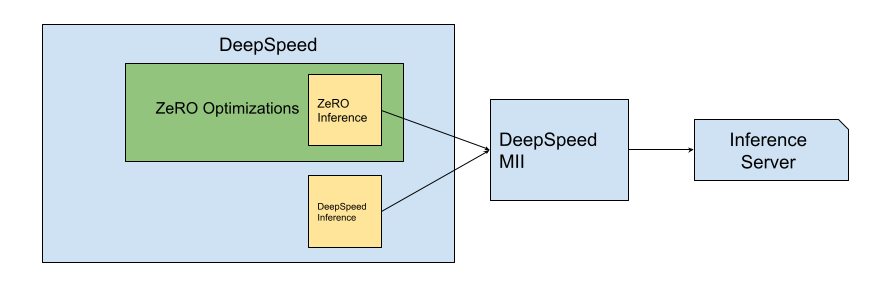
Fig 1: A figure demonstrating the hierarchy among DeepSpeed Libraries
TL;DR
Before we dive deeper, here’s the TLDR.
What do these libraries do?
Accelerate and ZeRO-Inference let you offload part of the model onto the CPU. Offloading helps you optimize the throughput of an inference service, even when the whole model fits on a GPU.
DeepSpeed Inference helps you serve transformer-based models more efficiently when: (a) The model fits on a GPU, and (b) The model’s kernels are supported by the DeepSpeed library. This is your go-to solution if latency is your main concern.
DeepSpeed MII is a library that quickly sets up a GRPC endpoint for the inference model, with the option to use either the ZeRO-Inference or DeepSpeed Inference technology.
When should you use these libraries?
During development: If you have idle GPUs left over from training, and you want to quickly see inference results from Hugging Face models, use Accelerate. It’s fast to install and easy to use to set up a workflow for experiments. However, some parts of this library are not yet optimized.
In production: If you want to host models on GRPC servers and optimize for a fast response, either in terms of latency or throughput, then DeepSpeed is the better choice.
Three sections
Still with me? Great. Now let’s dive into the details! This post is split into three sections:
How do these libraries work?
How do we set up and run these libraries (and what troubles might we encounter)?
Experimental results from implementing offloading with ZeRO-Inference
1. How do Accelerate and DeepSpeed work?
1.A. Accelerate
Developed by Hugging Face, “🤗 Accelerate is a library that enables the same PyTorch code to be run across any distributed configuration by adding just four lines of code!” (from their docs here). In other words, Accelerate can distribute a workload across your hardware, including GPUs and CPUs. While Accelerate can help with distributed training, for now let’s focus on inference.
Two main steps: planning and loading
Using Accelerate for large model inference can be roughly outlined in two steps: planning the load configuration, which is known as the “device map”; and loading the model according to the device map. Accelerate offers the following APIs to handle these steps:
Planning
init_empty_weights(): With this API, you can first initialize an empty model on what Hugging Face calls the “meta” device, using the model’s Hugging Face config file.infer_auto_device_map(): This API lets you plan the ideal device map according to your hardware and the model we just initialized. A device map is a dictionary that tells the library which layer of the model to load to what device. In its “auto” mode, Accelerate will try to load as many layers (sequentially) into GPUs, and then to CPUs or even the hard drive. An example device map looks like this:{0: “10GiB”, 1: “10GiB”, “cpu”: “30GiB”}
Loading
load_checkpoint_and_dispatch(): This API loads the model (for real) according to a device map.
Callouts for Accelerate
Here are a few things to note when you use Accelerate:
Check which blocks have residual connections. To do offloading, we have to divide our model such that layer n of a model is on GPU 0, and layer n+1 is on the next device. But make sure a block with a residual connection (e.g. Fig 2) is not split up this way. If required tensors are located on different devices, PyTorch will be angry. In the next section, we’ll go into how to determine which blocks shouldn’t be split, and how to pass that information to Accelerate.
Be aware that optimizations are in early stages. Today, several optimizations are still in early phases of development. For example, Hugging Face notes that “[t]he model parallelism used when your model is split on several GPUs is naive and not optimized, meaning that only one GPU works at a given time and the other sits idle.” Also, “[w]hen weights are offloaded on the CPU/hard drive, there is no pre-fetching (yet, we will work on this for future versions) which means the weights are put on the GPU when they are needed and not before.”
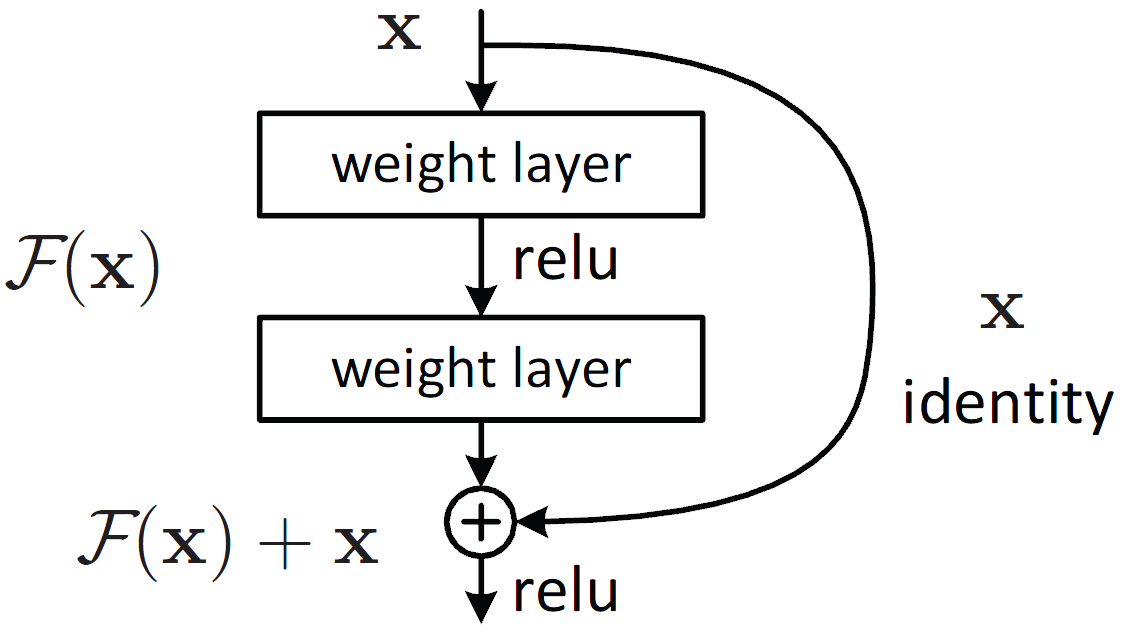
Fig 2: An example of residual connection
1.B. DeepSpeed
DeepSpeed offers two inference technologies, ZeRO-Inference and DeepSpeed-Inference. Here is a very good read about them by Heiko Hotz. Both of these technologies support multi-GPU computations.
In short, ZeRO-inference can help you handle big-model-small-GPU situations. As a member of the ZeRO optimization family, ZeRO-inference utilizes ZeRO stage 3 optimization. That means it offloads the parameters of the model onto other devices, and streams them back into GPUs when necessary. This not only enables batch computation on a GPU when a model can’t fit on one, but also enlarges the possible batch size for parallel computation on GPUs. (The caveat being that the communication time between RAM and VRAM becomes a bottleneck if there is too much offloading.) You can learn more about ZeRO-inference here.
DeepSpeed-Inference focuses on reducing latency when running inference with small batch sizes when the model is fully loaded into the GPU. It replaces a model’s inference kernels with the better-optimized DeepSpeed ones. For example, “DeepSpeed Inference can fuse multiple operators into a single kernel to reduce the number of kernel invocations and latency of main memory access across kernels.” There’s detailed documentation here and here.
Summary
ZeRO-Inference can help you with throughput by offloading a model onto CPU/NVMe, enabling a bigger range of batch sizes on GPUs.
DeepSpeed-Inference can help you reduce latency with better optimization and quantization. But you need to have a big enough GPU to host the model.
2. Implementation
Let’s start coding!
2.A Accelerate
To install Accelerate, simply run pip install accelerate if the transformers Hugging Face library is already installed. Follow the code snippet below to initialize an empty model, configure a device map, and load the model onto devices according to the mapping:
from accelerate import init_empty_weights from transformers import AutoConfig, AutoModelForCausalLM checkpoint = "EleutherAI/gpt-j-6B" config = AutoConfig.from_pretrained(checkpoint) with init_empty_weights(): model = AutoModelForCausalLM.from_config(config) from accelerate import load_checkpoint_and_dispatch model = load_checkpoint_and_dispatch( model, "sharded-gpt-j-6B", device_map="auto", no_split_module_classes=["GPTJBlock"] )
Note that in this example, we simply let the device_map argument (“auto”) infer the device map for us. You can also pass down the result from
infer_auto_device_map()todevice_map=.Here,
“sharded-gpt-j-6b”is the local directory where the sharded weights of the model were pre-downloaded.On the happy path, the model will be loaded onto your devices when you call
load_checkpoint_and_dispatch(). You might run into an issue with empty model initialization if you have multiple GPUs. For more information, see Appendix A.
As we mentioned before, you don’t want to split blocks that have residual highway structures so that intermediate tensors end up on different devices. You can tell the library which blocks not to split, by passing them as arguments in no_split_module_classes. You might wonder, in this example, how did we figure out we needed to specify the block [“GPTJBlock”]?
Every transformer model can be found here in the Hugging Face Github repo. And you can see that GPTJBlock is a class of nn.Module defined here. In general, you can find the corresponding model definition python file, get to know the detailed block compositions, and decide based on the block compositions what names to pass to no_split_module_classes=.
2.B DeepSpeed MII
Let’s now take a look at DeepSpeed MII. Before you begin, make sure the model you’re using is compatible with DeepSpeed, if you want to use DeepSpeed Inference. See if it’s covered by a policy here.
As with most Python libraries, you can easily install DeepSpeed MII through pip. (I did run into some installation issues stemming from python and PyTorch versions. For more details, see Appendix B and C.)
If you only want to use DeepSpeed Inference without a GRPC server, you can find a direct setup and tutorial here. Below, I’ll cover how to use DeepSpeed MII to deploy ZeRO Inference with a GRPC server.
To deploy a model through DeepSpeed MII, you must specify two configurations, ds_config (“DeepSpeed config”) and mii_config. Here’s a minimal working example you can follow to deploy a model locally onto your GPUs and test your installation:
import mii from transformers import AutoConfig # put your model name here MODEL_NAME="EleutherAI/gpt-j-6B" MODEL_DEPLOYMENT_NAME=MODEL_NAME+"_deployment" mii_config = {"dtype": "fp16"} name = MODEL_NAME config = AutoConfig.from_pretrained(name) ds_config = { "fp16": { "enabled": True }, "bf16": { "enabled": False }, "zero_optimization": { "stage": 3, "offload_param": { "device": "cpu", "pin_memory":True } }, "train_batch_size": 1, } mii.deploy(task='text-generation', model=name, deployment_name=MODEL_DEPLOYMENT_NAME, model_path=".cache/models/" + name, mii_config=mii_config, ds_config=ds_config, enable_deepspeed=False, enable_zero=True)
The example above enables ZeRO-Inference and offloads the model onto CPUs. Note that since ZeRO-Inference is still early in development, it has some weird behaviors we have to accept. For example, we still need to pass down the argument “train_batch_size”: 1 as if we’re running a training job.
If you just want to test DeepSpeed Inference, make the following adjustments:
In
mii.deploy(), setenable_deepspeed=Trueandenable_zero=False.Also there’s no need to provide the
“zero_optimization”key-value pair inds_config.
Once the model is deployed and running, you can query your model! You can use this example code:
import mii # put your model name here MODEL_NAME="EleutherAI/gpt-j-6B" MODEL_DEPLOYMENT_NAME=MODEL_NAME+"_deployment" generator = mii.mii_query_handle(MODEL_DEPLOYMENT_NAME) bs=3 inputs = ["DeepSpeed is", "Seattle is", "Preemo Inc is"] result = generator.query({"query": inputs}, do_sample=True, max_new_tokens=50, batch_size=bs)
Note that though the point of using GPU is to utilize its batch inference capability, for some models, ZeRO-inference can’t do batch inference out of the box². See Appendix D for a workaround.
² To illustrate, note here that we can pass down parameters specific to the Hugging Face model only on the pipeline level, such as batch_size or max_new_tokens. However, for some models, we need to change tokenizer-level settings that are not reachable by the generator (mii_query_handle).
3. Experiments and thoughts on offloading and throughput optimization
Let’s now return to the original task that got me down this rabbit hole: getting an LLM to perform well on my limited hardware. Let’s see how the libraries we just talked about helped.
I compared the inference throughput between using just CPU, versus using GPU with CPU offloading from ZeRO-Inference, using a synthetic dataset. I hosted the gpt-j-6B model with an AWS g4 instance, equipped with a 16 GB T4 GPU, and tested the throughput on batch sizes of 50, 100, 150, and 200.
From the figure below, you can see the throughput on GPU scaled almost linearly (until it OOM-ed) even with offload, whereas CPU-only scaled poorly as the batch size increased.

You might point out that in a real application, your mileage may vary due to the varying length of sentences in a batch. For example, if one batch has a very long sentence, that batch could result in an OOM error with even a smaller batch size. This can cause the OOM point to happen before a GPU can earn a solid advantage, especially when you factor in the cost of GPUs.
But this brings us to another advantage of offloading. Offloading more of the parameters into CPU frees up more space in the GPU and allows for a bigger batch size, which gives GPU inference better throughput. For this reason, you might consider using offloading even if the model can fit on the GPU. The bigger the GPU, the more you can gain from offloading. However, the offloading amount will eventually be bottlenecked when the traffic between CPU and GPU slows down the whole process.
Considering all these factors — cost, IO speed, offload amount, batch size — the ideal solution and setup for inference really requires a case-by-case study.
Conclusion
This post offered a high-level overview of the two libraries, Accelerate and DeepSpeed and their applications to large model inference. Accelerate is a hassle-free launcher for Hugging Face models and can help developers quickly get inference results during experiments. DeepSpeed, on the other hand, provides an end to end customizable inference solution for production. These libraries enable models to be hosted on smaller hardware, and provide better optimization options even when the GPU is big enough to host a model directly.
Appendix: Known issues/Workarounds
for DeepSpeed 0.8.3 and Accelerate 0.17.0
If you have more than one GPU, and let the device map be auto generated, you might run into the following error with Accelerate:
weight is on the meta device, we need a `value` to put in on 1. This means the library got confused when loading directly from the “meta” device to your second GPU (for example cuda:1). A quick workaround is to remove thewith init_empty_weights():line so that the model is “for real” loaded into the CPU.DeepSpeed-MII depends on
asyncio, as specified in their repo here. However, this library has been internalized into Python 3.4. If DeepSpeed-MII is not installed through pip, another package manager might have trouble installing that library.If you encounter the error
Unable to build extension “transformer_inference”, it may be due to the PyTorch version and build. This post provides a workaround, which is to downgrade the PyTorch version to 1.12. Installing it via conda solved it for me:conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch -ySince DeepSpeed MII sets up the Hugging Face inference pipeline for you, you can only pass down arguments that make modifications on the pipeline level. However, some models can only do batch inference if the tokenizer is configured in a certain way. This post discusses this issue. So far there is no official support for tokenizer-level configurations in DeepSpeed MII. The workaround is to manually inject some tokenizer settings, such as
pipe.tokenizer.pad_token_id = pipe.model.config.eos_token_id, when the pipeline is initiated. To do that, you need to modify the DeepSpeed-MII code, then do anotherpip installas suggested by the post.